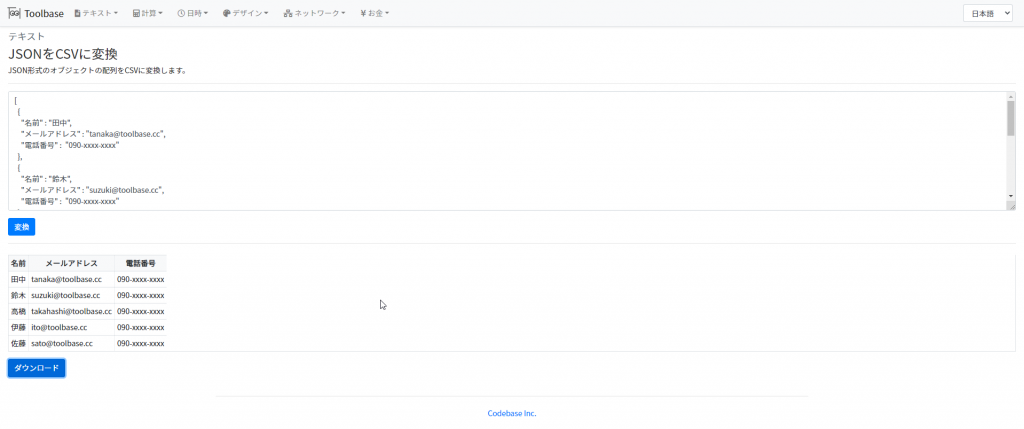
まず、コンテナからイメージを作成します。
$ docker commit <コンテナ名> <イメージ名>イメージをTARファイルに保存します。
$ docker save <イメージ名> -o <ファイル名>まず、コンテナからイメージを作成します。
$ docker commit <コンテナ名> <イメージ名>イメージをTARファイルに保存します。
$ docker save <イメージ名> -o <ファイル名>CentOS環境において、誤ってDockerのコンテナを起動したまま、yumでdocker-ceパッケージをアップデートしてしまいました。
その後、再度コンテナを起動しようとしたのですが、次のエラーにより起動ができない状態になりました。
$ docker start postfix
Error response from daemon: OCI runtime create failed: container with id exists: d21dd44a4cd471de93a5869922288143d7a1e2395f90b9bee9dc4ca5476524cc: unknown
Error: failed to start containers: postfix次のフォルダにある、コンテナ名を持つフォルダを削除することで、起動が可能になりました。
/run/docker/runtime-runc/mobyターミナルでhistoryコマンドを実行すると、過去に実行したコマンドの一覧を見ることができて便利です。特定のコマンドを抽出したい場合は、次のようにgrepコマンドと組み合わせます。
$ history | grep ssh結果はこのような感じで返ってきます。
14 ssh example.com
15 ssh test@example.com
121 ssh test@example.jp表示されたコマンドを再度実行する場合は、コマンドをコピペしても良いですが、一緒に表示される番号の頭に「!」をつけて
$ !121としても、コマンドを再度実行することができます。
これでも十分便利なのですが、次の方法を使うと、過去のコマンド履歴を使って、入力中のコマンドを補正することができます。
ホームディレクトリに次のファイルをコピーし、
$ cp /etc/inputrc ~/.inputrc次の内容を追記して保存します。
"\e[A":history-search-backward
"\e[B":history-search-forwardこれで、コマンドの入力中にキーボードのカーソルの「↑」を押すと、それまで入力したコマンドに前方一致する過去のコマンドの履歴を一つずつ確認することができます。また、履歴を遡った後に「↓」を押すと、一つ直近のコマンドに戻ります。
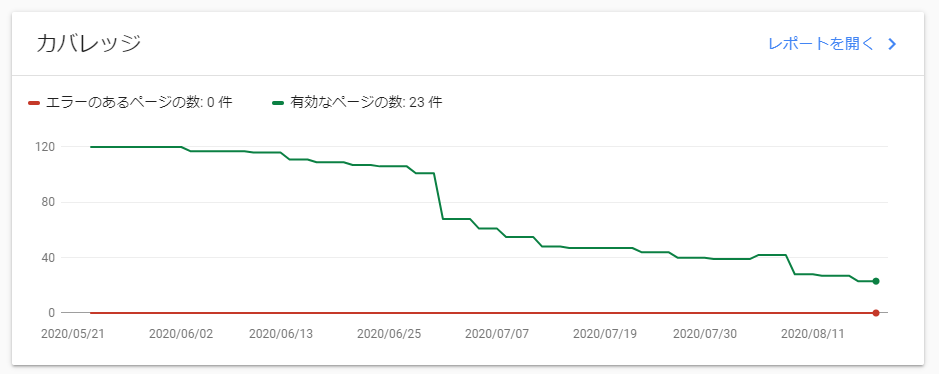
弊社で運用しているWebサイトにおいて、サイトのページがGoogleのインデックスからどんどん外されるという現象が発生しました。
Google Search Consoleでカバレッジを確認すると、次のようにどんどん下がっているのが確認できます。
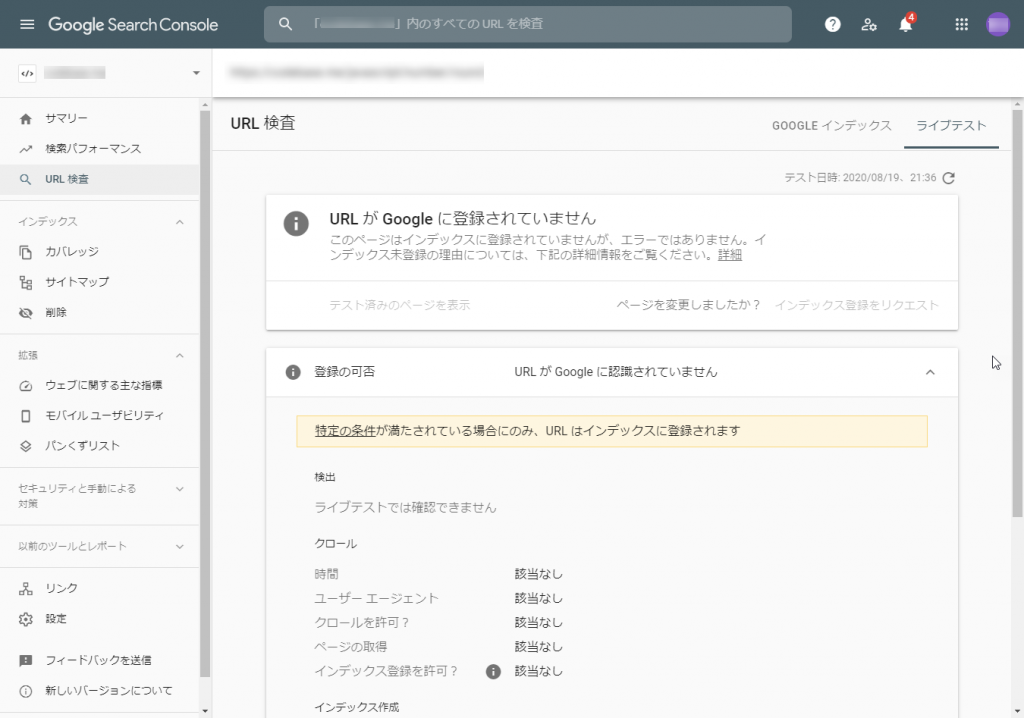
外されたページの一つに対して、「インデックス登録をリクエスト」を行うと、次のように「URLがGoogleに認識されていません」というエラーが返ってきました。
また、Googleのモバイルフレンドリーテストを試すと、次のようなエラーが返ってきました。
ページにアクセスできません
ページが利用できない、ページが robots.txt によってブロックされているといった理由が考えられます
当該ページは、ブラウザでアクセスをすると問題なく表示できますし、robots.txtは設置していないので不思議でしたが、とりあえずrobots.txtを設置してみるとエラーが解消されました。
色々調べてみると、当サイトでは動的なURLを処理する仕組みが原因で、存在しないファイルにアクセスしようとした際にHTTPステータスコード404ではなく、500を返す状態になっていました。よってGoogleのシステムがrobots.txtを見に行ったときも500が返されていました。
Googleのインデックスへの登録にrobots.txtは必須ではありませんが、その場合はしっかりと404を返す必要があるようです。その他のステータスコードは試していませんが、少なくとも500を返すと、Googleはサイト全体がサーバー内部エラーと判断するのか(または、サイトクロールの可否を判断できないからか)、サイト内の他のページにもアクセスできなくなるように思われます。
Windowsにmemcachedをインストールした際のメモです。
まず、Windows用のバイナリを次からダウンロードします。バージョン1.4.5以降はWindowsのサービスへの登録に手間が掛るので、今回は1.4.4をダウンロードします。
http://downloads.northscale.com/memcached-win32-1.4.4-14.zip
ダウンロードしたZIPファイルを展開し、適当な場所に配置します。
C:\memcached管理者権限でコマンドプロンプトを立ち上げ、上記のフォルダに移動します。
> cd C:\memcached次のコマンドでmemcachedをWindowsのサービスとして登録します。
> memcached.exe -d install登録が完了したら、サービスを起動します。
> memcached.exe -d start以上でMemcachedのインストールは完了です。
サービスの停止およびアンインストールの際は、次のコマンドを使用します。
> memcached.exe -d stop
> memcached.exe -d uninstallmemcachedに接続して状態を確認するには、Telnetを利用するのが便利です。
Telnetを起動するには、コマンドプロンプトでtelnetコマンドを実行します。memcachedのポートは標準で11211になります。
> telnet localhost 11211telnetコマンドが見当たらない方は、「Windowsの機能の有効化または無効化」から「Telnetクライアント」をインストールすることで使用できるようになります。
接続後、memcachedの各コマンドを利用できるようになります。
上記NorthScaleのサイトからは64 bit版のバイナリもダウンロードすることができます。
http://downloads.northscale.com/memcached-win64-1.4.4-14.zip
ただ、環境に固有の問題かもしれませんが、内部のタイムスタンプにバグがあるように思われます。
そのため、memcachedに値を登録する際にうまく有効期限を設定できないトラブルに見舞われました。memcachedでは、30日以内に関しては期限切れまでの秒数、それ以降に関してはUNIXタイムスタンプで期限の日時を指定する仕様になっているのですが、UNIXタイムスタンプで指定した場合に即座に期限切れになってしまう問題が発生しました。
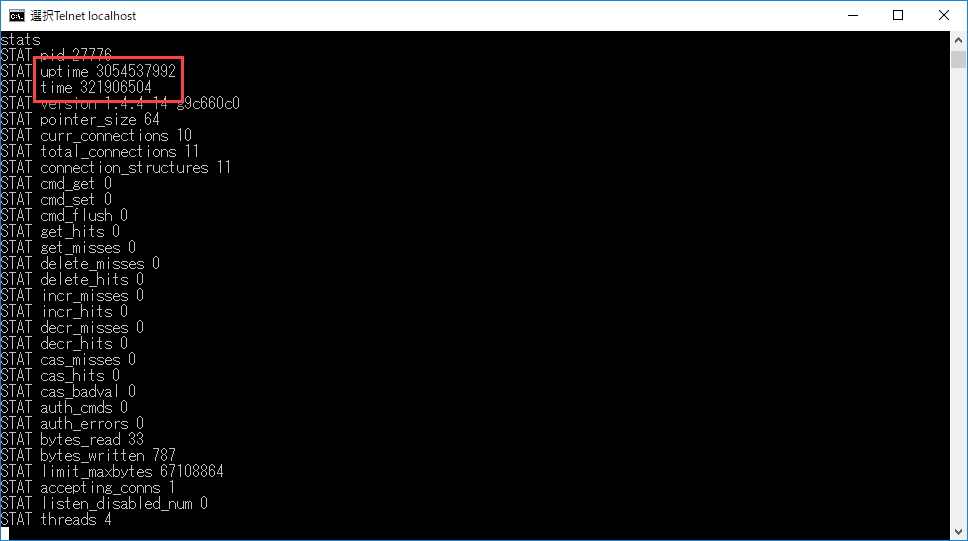
最初は原因が分からず大変苦労しましたが、Telnetで接続後、statsコマンドを使用したところ、memcachedサーバーの時刻と起動からの経過時間の値がおかしなことになっていることに気付きました。
旧バージョンのXAMPPのダウンロードサイト
https://sourceforge.net/projects/xampp/files/
Apache、MySQL、PHPのバージョンの対応表
https://blog.e2info.co.jp/2015/01/10/xampp-apache-mysql-version/
PHPではfile_get_contentsという強力な関数があり、ローカルファイルでもWebサイトでも、その内容を簡単に取得することができます。
例えば、Livedoorの天気情報APIから東京の天気を取得するには、
<?php
$res = file_get_contents('http://weather.livedoor.com/forecast/webservice/json/v1?city=130010');
$weather = json_decode($res, true);とするだけです。(JSON形式で返ってくるため、json_decodeでデシリアライズして連想配列に格納しています。)
一度利用するだけのスクリプトであればこれで十分かと思いますが、運用環境であればエラーハンドリングも必要になってくると思います。その点も踏まえながら、次にGETリクエストとPOSTリクエストについて、詳しい使い方をお伝えします。
file_get_contentsにURLを指定した場合、標準では、HTTPステータスコードが4xxや5xxの場合にWarningエラーが発生し、レスポンスボディを取得することができません。次のようにignore_errors属性を定義したcontextを作成し、第三引数に渡すことで、4xxや5xxの場合でも取得できるようになります。
<?php
$context = stream_context_create([
'http' => [
'ignore_errors' => true
]
]);
$res = file_get_contents('<URL>', false, $context);次に、HTTPステータスコードに応じたエラー処理ですが、file_get_contentsを実行すると、$http_response_header変数にレスポンスヘッダが自動的にセットされるため、これを利用します。
HTTPステータスコードは1行目に含まれるので、
$http_response_header[0]の値に応じて、処理を切り分けると良いかと思います。値は「HTTP/1.1 200 OK」という形式になっていますので、下の例では、strpos関数を使ってステータスコード200が含まれるかチェックしています。
if (strpos($http_response_header[0], '200') !== false) {
// HTTPステータスコードが200(正常)だった場合の処理
// ...
} else {
// それ以外の場合の処理
// ...
}ステータスコードを厳密に抽出したい場合は、正規表現を使います。
preg_match('/HTTP\/1\.[0|1|x] ([0-9]{3})/', $http_response_header[0], $matches);
$statusCode = $matches[1];file_get_contentsは標準でGETリクエストになりますが、上述したcontextのmethod属性にPOSTを指定することで、POSTリクエストを投げることもできます。
$headers = [
'Content-Type: application/x-www-form-urlencoded'
];
$body = [
'field1' => 'value1',
'field2' => 'value2'
];
$context = stream_context_create([
'http' => [
'method' => 'POST',
'header' => implode("\r\n", $headers),
'content' => http_build_query($body, '', '&'),
'ignore_errors' => true
]
]);
$res = file_get_contents('<URL>', false, $context);HTTPリクエストヘッダはheader属性、リクエストボディはcontent属性に値を設定します。ここでは、それぞれ配列と連想配列でデータを準備し、implodeおよびhttp_build_query関数を利用して必要なフォーマットに整形した上で、各属性に割り当てています。
Railsでは、redirect_toメソッドに対してモデルのオブジェクトを渡すと、そのオブジェクトを表示するページに簡単に遷移させることができます。
# /users/<id> に遷移
redirect_to @userただ、アンカー(ページ内での位置)を指定するには少し工夫が必要で、次のように指定します。
# /users/<id>#description に遷移
redirect_to user_path(@user, anchor: 'description')※user_pathはroutes.rbで定義しておく必要があります。
LaravelではMailableクラスを使用することで、メールの組み立てと送信を簡単に行うことができます。
Mailableクラスを作成するには、artisanコマンドを使うと簡単です。
$ php artisan make:mail MyMailableこのコマンドを実行すると、app/Mail/MyMailable.phpというファイルが作成され、中身は次のようになります。
<?php
namespace App\Mail;
use Illuminate\Bus\Queueable;
use Illuminate\Mail\Mailable;
use Illuminate\Queue\SerializesModels;
use Illuminate\Contracts\Queue\ShouldQueue;
class MyMailable extends Mailable
{
use Queueable, SerializesModels;
/**
* Create a new message instance.
*
* @return void
*/
public function __construct()
{
//
}
/**
* Build the message.
*
* @return $this
*/
public function build()
{
return $this->view('view.name');
}
}buildメソッドの戻り値として、レンダリングされたテンプレートを返すことで、メッセージの送信が完了します。
メッセージの送信後に実行したい処理がある場合は、Mailableクラスのcallbacksプロパティ(配列)に関数をセットします。コールバック関数の引数には$message(Messageオブジェクト)が渡されるため、$message->getId()でメールサーバーから返されたMessage-IDを取得することもできます。
public function build()
{
$this->callbacks[] = function($message) {
// 送信後に実行したい処理
};
return $this->view('view.name');
}